


White paper: Demystifying Semantic Search - A Comprehensive Guide to Implementing Semantic Search Engines
1. Introduction
Search is at the heart of many industries - from E-commerce (B2B & B2C) to marketplaces, SaaS, and media companies. This white paper navigates through search methodologies, transitioning from conventional keyword-based to advanced semantic approaches, addressing their limitations and exploring the implementation of a semantic search engine using an open-source language model.
2. Keyword search
When thinking about search, we typically think of keyword-based search, in which we search for exact matches for a provided query in a corpus (set of available data).
Keyword searching matches words with words, words to synonyms, or words to similar words.
However, keyword searching is limited due to its incapacity to incorporate the meaning of the query into the search problem. This results in closely related terms being neglected and all terms in the query being evaluated independently instead of as a unit with semantic meaning.
These shortcomings end up hampering the product user experience, as it is common for keyword searches to return false positives (i.e., irrelevant or only partially relevant results).
Several techniques and heuristics are used to improve upon the naive implementation of keyword-based search, but there is no one-size-fits-all, and they need to be evaluated on a case-by-case basis. Some of the most common include:
- Term weighting: TF-IDF (Term Frequency-Inverse Document Frequency – a statistical measure of term relevance, calculated as the product of its in-document frequency and the inverse frequency of that term across the corpus).
- Query expansion: tokenization, stop word removal (e.g., “is”, “which”, “on”), stemming and lemmatization (reducing words to their root form).
- Phrase searching: n-grams (contiguous sequences of n items – used to account for immediate term context).
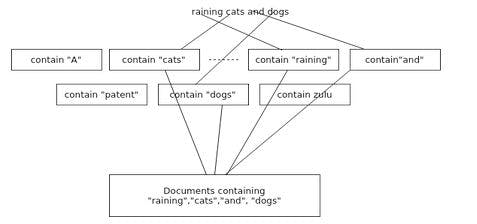
3. Semantic search
Semantic search approaches the search problem by incorporating the meaning of the query terms according to their context. By analyzing the context of words within the query and their relationships, semantic search engines aim to comprehend user intent, leading to more relevant and accurate search results.
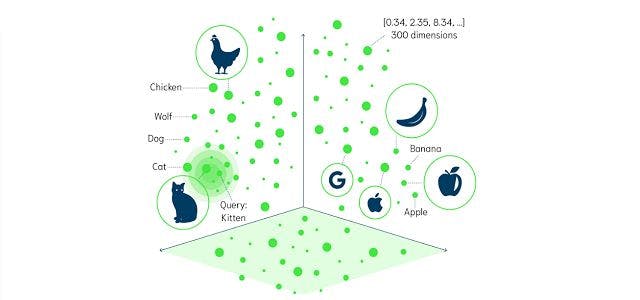
3.1. Vector Embeddings
The meaning of the query is captured by a vector embedding – a numerical representation of data (e.g., text. images, or audio), which facilitates the analysis and manipulation of the input data for downstream tasks (e.g., prediction or classification).
Vector embeddings are usually obtained using vector embedding models – a type of predictive model trained to encode input objects into vectors. Resulting vectors are commonly highly dimensional (over one thousand dimensions) and dense (all values are non-zero – this is in contrast to sparse models, such as one-hot encoding; this allows for capturing complex relationships, such as analogy relationships, with the additional advantage of being more space-efficient).
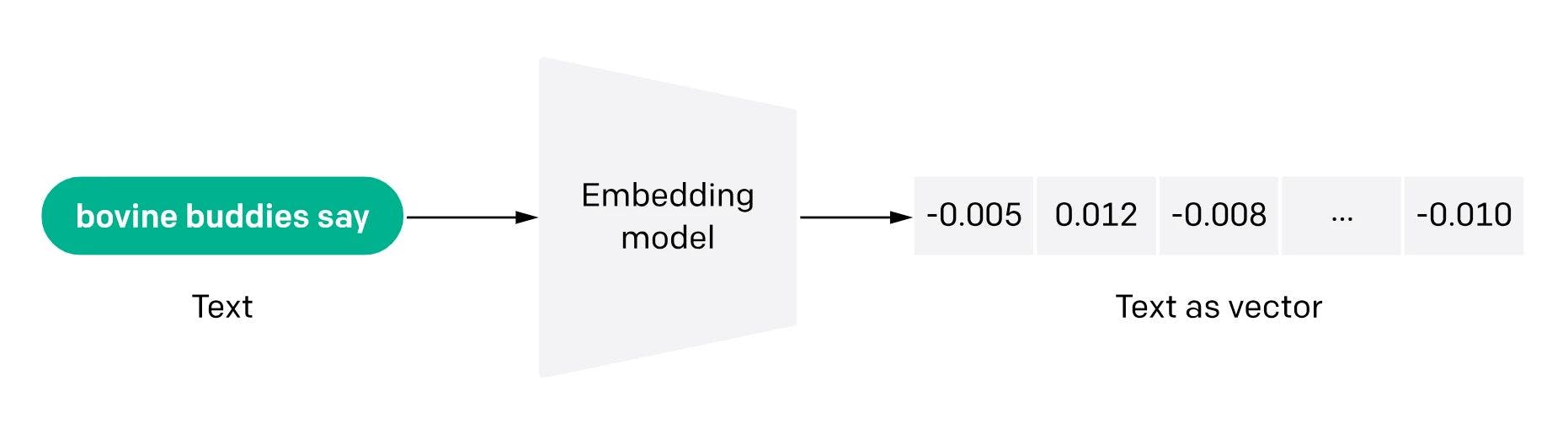
3.2. Embeddings in NLP
In the context of Natural Language Processing (NLP), we can discern between word or sentence-level embedding models. Additionally, these models may follow a static or contextualized (context-dependent) approach:
- Word-level embeddings produce an embedded representation of a word, while sentence representation encodes whole sentences and, therefore, is an extension of the principle of word-level embeddings.
- Context-dependent embeddings extend basic word embeddings by incorporating contextual information (e.g., surrounding words in a sentence or the topic of the source document).
In terms of the underlying model architectures, there exist multiple approaches – while most widely used models are based on deep neural networks, they still differ in their structure and training process. For example, Word2Vec and GloVe are based on Recurrent Neural Networks (RNN), with more recent models being based on the transformer architecture (e.g., BERT).

Some of the most popular word embedding models include:
- Word2Vec (two approaches: Continuous Bag-of-Words – trained to predict a word in a given context, and Skip-N Gram – trained to predict the context given the word).
- GloVe (Global Vectors for Word Representation – trained on an aggregated global word-to-word co-occurrence matrix from a given corpus).
- BERT (Bidirectional Encoder Representations from Transformers – bidirectional encoder-based transformer model; two 110M and 340M parameters variants).
Most vector embedding models provide public pre-trained model weights trained on large corpora of text datasets (e.g., Wikipedia or Common Crawl). For most use cases (i.e., not involving obscure, domain-specific language), pre-trained weights are adequate enough for use due to their diverse training data, which results in a vector space capturing a wide range of syntactic and semantic word relationships.
3.3. Similarity Measures
Once we have obtained the vector embeddings for our corpus, we can compute how “similar” or “close” they are in our vector space.
When searching our vector space based on a given query, we first compute the vector embedding of the search query, and then we proceed to retrieve those vectors spatially closer to it – this process is known as nearest neighbor search (NNS).
However, to determine the closeness of our vector embeddings, we need to define a similarity metric.
Similarity metrics are a type of distance measurement used to quantify the similarity (i.e., distance) between two vectors in space. The choice of similarity metric is highly problem-dependent.
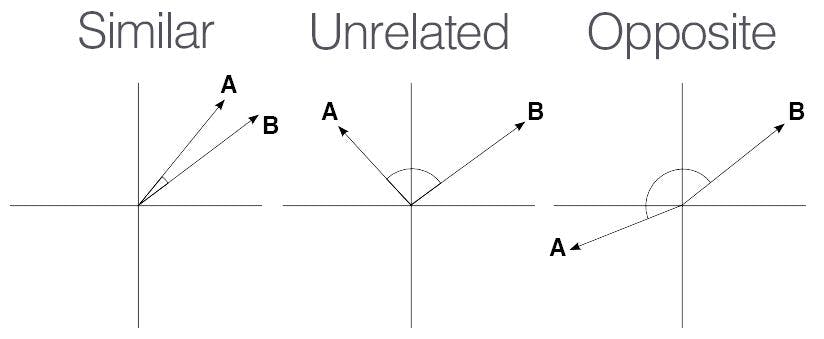
Some common similarity measures used in embedding spaces are:
- Cosine similarity (measures the cosine of the angle between two vectors – captures the directional rather than magnitude difference between vectors).
- Euclidean distance (measures the “straight line” distance between two vectors).
- Manhattan (L1) distance (sum of the absolute differences between the coordinates of two vectors - relevant in scenarios where dimensions are not directly comparable).
3.4. Nearest Neighbour Search (NNS)
There are multiple approaches to performing nearest neighbor search. Most large-scale production systems use approximate nearest neighbor (ANN) algorithms instead of a brute force approach, in which all vector-to-vector distances are computed (i.e., quadratic time complexity or O(n^2)).
Therefore, even though brute force search guarantees exact nearest neighbor search, it is very computationally expensive and proves infeasible for large embedding stores.
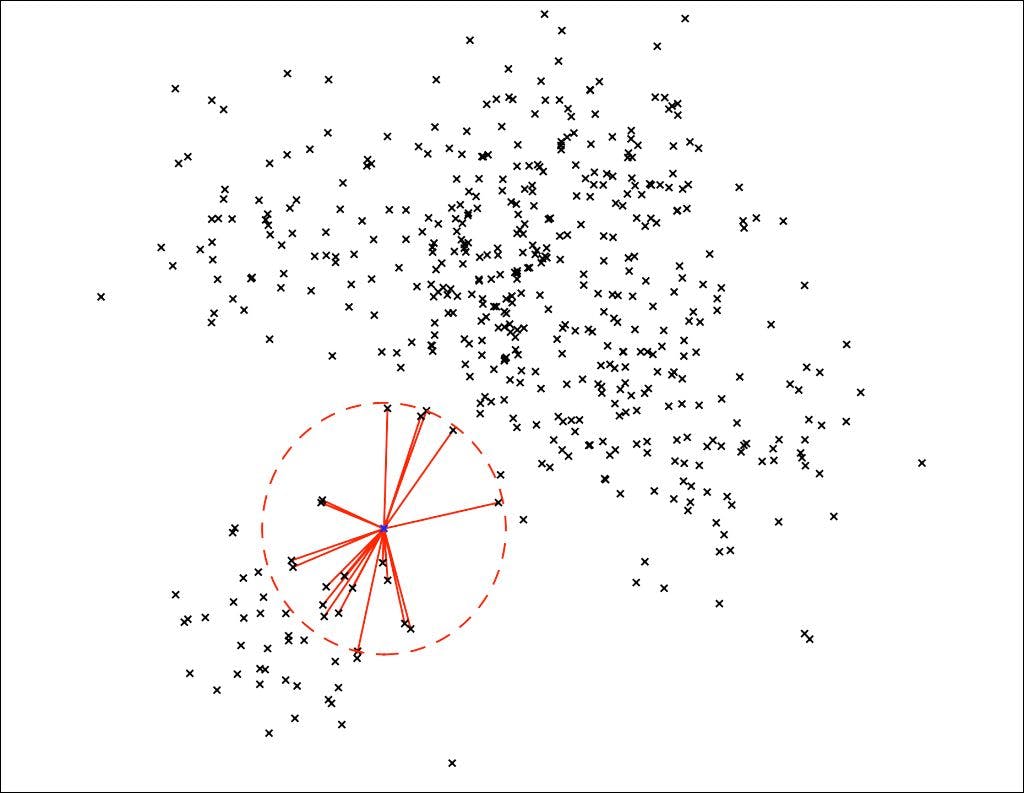
Some of the most common ANN algorithms include:
- Locality-Sensitive Hashing (LSH): hashes input items to map similar items into the same buckets.
- Random Projection Forest (rpForest): dimensionality reduction technique by projecting data onto randomly generated subspaces, repeating this process multiple times, forming a “Random Projection Forest”).
- K-D Trees: extension of the KNN (K-Nearest Neighbors) algorithm that organizes data into a hierarchical structure for faster searching.
- Annoy (Approximate Nearest Neighbors Oh Yeah): builds a forest of binary search trees for approximate nearest neighbor search.
3.5. Vector Stores
Lastly, we need some form of storage for our computed embeddings – once the word embeddings are computed for the corpus, they can be stored and reused for future similarity searches without recomputing them each time.
Vector databases are databases designed to store and manage vector embeddings efficiently and to perform operations like similarity search in an optimized way. These databases are designed to handle high-dimensional data and provide efficient search algorithms (like the ANN algorithms mentioned above), which can be significantly faster than scanning through all vectors (i.e., brute-force) in a high-dimensional space.
Some examples of open-source, popular vector databases include Faiss (developed by Facebook), Pinecone, Chroma, and Milvus; additionally, projects such as pgvector for Postgres bring similarity search to proven DBMS.
4. Hybrid approaches
It is important to note that a purely semantic search approach may not provide an optimal user experience, as it lacks real-time information about the results (e.g., stock information, discounts, promotions, or context about previous user interactions).
For this reason, hybrid approaches incorporate additional metadata to post-process the semantic search results, effectively filtering and ranking the raw search results.
5. A practical use case
We will now introduce a practical use case in which we have develop a semantic search engine for an E-commerce product catalog.
The idea behind this implementation is to leverage an off-the-shelf (pre-trained) language model, in order to infer the meaning of the textual descriptions of the products, enabling semantic searching of the catalog.
The code for this implementation can be found in our GitHub repo. Additionally, we provide a docker-compose file in order to locally set up all the external dependencies required to replicate the use case.
For this use case, we have used the Wayfair Annotation Dataset (WANDS). This dataset includes over 40,000 unique products with additional metadata, including textual descriptions.
In terms of the language model, we opt for all-MiniLM-L12-v2, a fine-tuned, sentence-embedding version of the MiniLM language model – a transformer-based language model developed by Microsoft, intended as an efficient alternative to larger models (e.g., MiniLM – 33M parameters, BERT – 109M parameters).
The implementation takes the following approach:
- Load, pre-process and store the product catalog using Spark
- Download the pre-trained sentence embedding model from HuggingFace Model Hub, using sentence_transformers
- Use LangChain to load the processed data, compute the embeddings for each product and store the computed embeddings in Chroma
- Use MLFlow to build a deployable model
5.1. Loading, Pre-Processing and Storage of Catalog Data
First, we need to preprocess the dataset. In this project, we have chosen Spark to load the original dataset, process it, and store the results. Due to the limited scope and dataset sizes of this proof of concept, we could have opted for using Pandas as a more user-friendly (offers a higher level, simpler API), in-memory option for our data pipeline, as we are not taking advantage of the distributed nature of Spark.
Regarding the storage of the preprocessed data, we use Parquet – a columnar storage file format that provides efficient compression and encoding schemes.
5.2. Download Language Model
We use the sentence-transformers library to download the all-MiniLM-L12-v2 language model. We can not directly use Hugging Face’s Transformers library because it does not provide support for sentence embeddings out of the box. sentence-transformers offers a wrapper around Hugging Face Transformers, enabling the use of sentence-level embedding models.
We then read the downloaded model using the HuggingFaceEmbeddings LangChain wrapper. This allows us to leverage the abstractions provided by LangChain in regards to document processing and, helper utilities for handling embeddings.
In addition, thanks to the unified interface that LangChain provides through the HuggingFaceEmbeddings wrapper, we can further evaluate alternative pre-trained language models preserving the rest of the implementation.
5.3. Compute the Product Embeddings
Using the LangChain wrappers for document loading and Chroma, we load the pre-processed data, compute the product embeddings using our language model, and store the resulting embeddings into Chroma.
5.4. Use MLFlow to build a deployable model
MLflow is an open-source platform for managing the machine learning model lifecycle, spanning the experimentation, reproducibility, and deployment phases.
For our implementation, we have opted to build our model with mlflow.pyfunc.PythonModel – a generic Python model that allows the encapsulation of any Python code that produces a prediction from an input. It defines a generic filesystem format for Python models and provides utilities for saving and loading them to and from this format.
When a model is encapsulated in mlflow.pyfunc.PythonModel, it enables:
- Model storage to disk, using the MLFlow model format (using mlflow.pyfunc.save_model) – a self-contained format for packaging Python models that allows you to save a model and later load it back to produce predictions.
- Serving predictions via REST API using mlflow.pyfunc.serve, or as a batch inference job.
6. Conclusion
The white paper underscores the evolution from traditional keyword-based searches to more sophisticated semantic methods, illuminating their pivotal role in enhancing search precision and user experience across diverse industries reliant on efficient information retrieval systems. By showcasing the practicality of leveraging semantic approaches and advanced models like MiniLM-L12-v2 on datasets such as WANDS, the paper emphasizes the tangible benefits of embracing context-based search. This shift has far-reaching implications, offering opportunities for improved decision-making, enhanced customer interactions, and streamlined operations, ultimately fostering innovation and competitive advantage in the ever-evolving landscape of information retrieval and data-driven industries.
7. How can Nieve help?
Our team specializes in harnessing the capabilities of the various LLMs (e.g. OpenAI), particularly integrating technologies like ChatGPT into your products and services. We develop practical applications that leverage generative AI to enhance user experiences, drive automation, and enable intelligent interactions.
Furthermore, our machine learning model training and design services ensure that your business can extract actionable insights from your data. Whether it's predictive analytics, anomaly detection, or data-driven decision-making, our experts will guide you every step of the way.
Lastly, Nieve stands out with its proficiency in crafting custom ChatGPT plugins that are finely tuned to your distinct needs. These plugins, which operate directly from within the ChatGPT interface, are designed to elevate your conversational experiences and amplify productivity by leveraging AI-fuelled interactions with your own products or services.
With Nieve as your partner, you can unlock the full potential of ChatGPT and modern LLMs and embark on an AI-powered journey that drives innovation and growth. Whether it's sentiment analysis, AI-powered reporting, Interactive guides, AI chatbots, ChatGPT plugins or conversational search, we have the expertise to turn these possibilities into tangible projects. Embrace the power of generative AI with Nieve, and together, let's transform the way you engage with customers and drive business success.
Contact:
Mikaela Nyman, CEO
Nieve Consulting Services SL
mikaela@nieveconsulting.com
+34 610 096 740
+358 50 553 8001


